Para estudiar la posible relación entre el número de satélites (cangrejos macho a su alrededor) y la anchura del caparazón de los cangrejos hembra tipo herradura, se realizó un experimento con 8 cangrejos hembra a los que se midió:
la anchura de los caparazones (\(x\)), medida en cm.
el número total de cangrejos macho que se utilizaron en el experimento para cada hembra (\(n\)).
el número de satélites o cangrejos macho que se situaron alrededor de cada hembra.
El objetivo es modelizar la proporción de satélites en función de la anchura del caparazón. Los datos se recogen en la siguiente tabla:
Anchura
Satélites
Total
23.25
5
14
23.75
4
14
24.75
17
28
25.75
21
39
26.75
15
22
27.75
20
24
28.75
15
18
29.25
14
14
Responde a las siguientes preguntas:
1. Introduce los datos en R mediante la función data.frame.
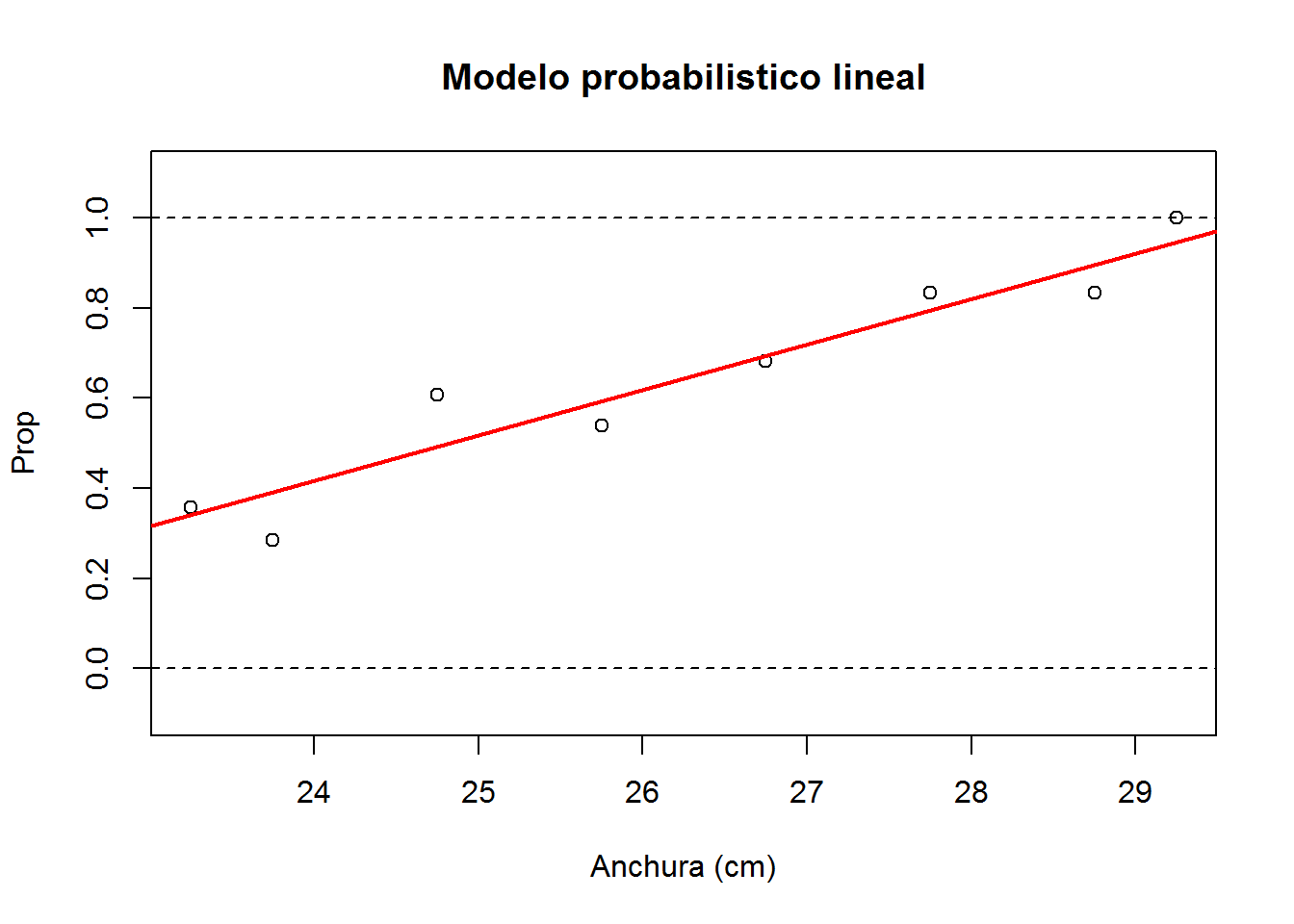
3. Ajusta el modelo probabilistico lineal \[\pi(x)=\alpha + \beta x\] donde \(y\) corresponde a la variable prop y \(x\) corresponde a la variable anchura
Call:
lm(formula = prop ~ anchura, data = cangrejos, weights = total)
Weighted Residuals:
Min 1Q Median 3Q Max
-0.39848 -0.28671 -0.00139 0.18904 0.60386
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.00206 0.39604 -5.055 0.00232 **
anchura 0.10081 0.01507 6.692 0.00054 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3641 on 6 degrees of freedom
Multiple R-squared: 0.8818, Adjusted R-squared: 0.8621
F-statistic: 44.78 on 1 and 6 DF, p-value: 0.0005402
¿Cuáles son las estimaciones de los coeficientes? ¿Son estadísticamente significativos?
Las estimaciones de los coeficientes del modelo son: \(\hat{\alpha}=-2.002\) y \(\hat{\beta}=0.101\)
Ambos coeficientes son estadísticamente significativos, ya que los p-valores son pequeños.
¿Cuál es el coeficiente de determinación? Explica su significado.
\(R^2_\mbox{adjusted}=0.8621\). Es decir, el 86.21% de la variabilidad total es explicada por el modelo de regresión (variable`anchura).
¿El modelo ajustado es estadísticamente significativo?
Sí, el modelo es estadísticamente significativo. La función anova() presenta el análisis de la varianza con la descomposición de la variabilidad total en sus fuentes de variación y nos indica que la variable anchura es estadísticamente significativa.
4. ¿Cuáles son las predicciones de la proporción de satélites para cada valor de la anchura observada? ¿Y el número esperado de satélites por hembra?
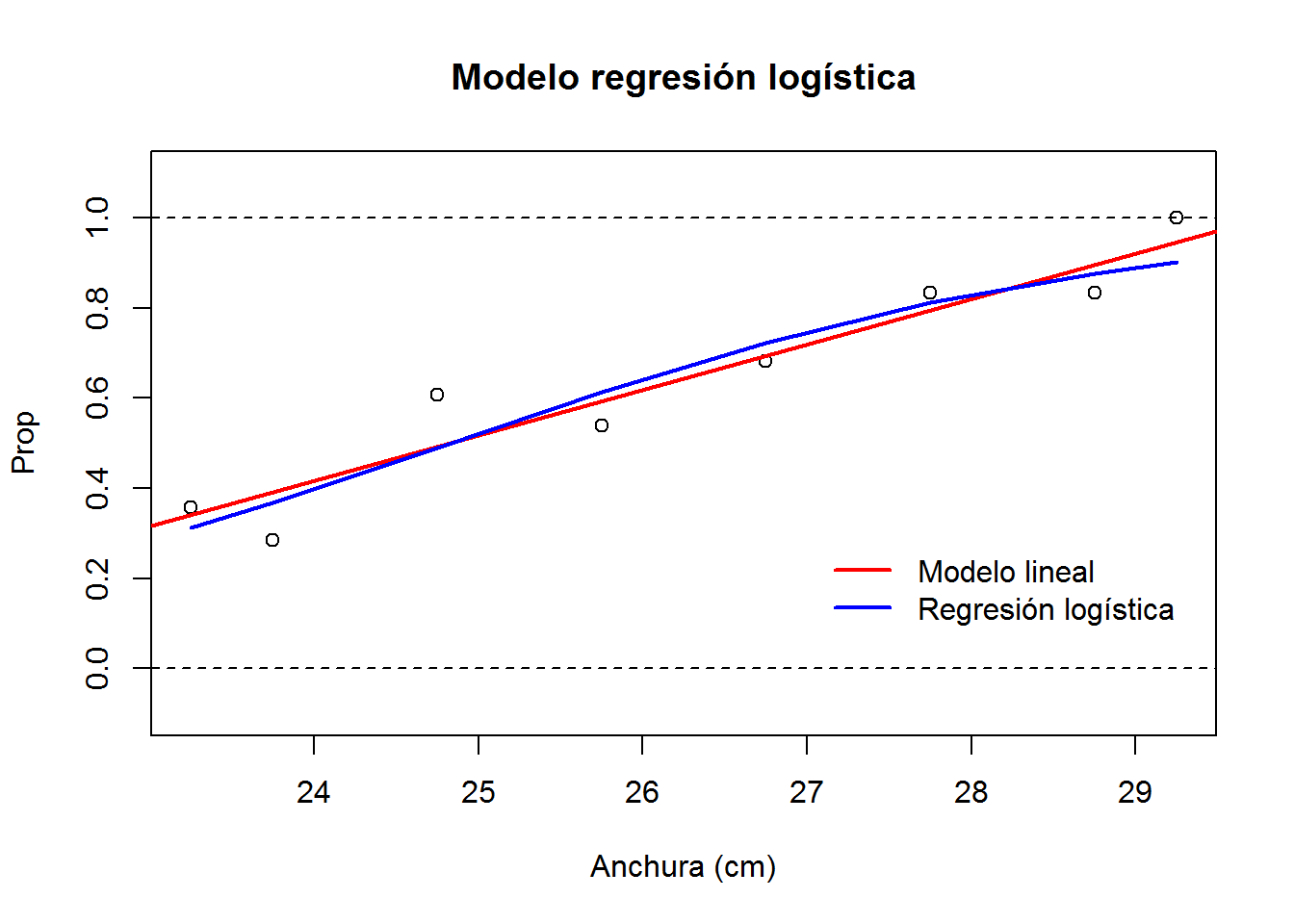
6. Ajusta el modelo de regresión logística \[\mbox{logit}[\pi(x)] = \log \left(\frac{\pi(x)}{1-\pi(x)} \right) = \alpha + \beta x\] donde \(\pi\) corresponde a la variable prop, y \(x\) a la variable anchura.
9. ¿Cuánto crece el odds estimado (odds ratio) por cada cm de aumento del caparazón? Proporciona un intervalo de confianza al 95%.
Cuando la anchura del caparazón aumenta en 1 cm, el odds ratio (\(OR=e^\beta\)) es de
exp(coef(modelo2)[2])
anchura
1.650584
Es decir, por cada incremento de 1 cm en la anchura del caparazón el odds estimado crece aproximadamente un 65%.
Para calcular un intervalo de confianza al 95% de \(e^\beta\), debemos exponenciar los límites inferior y superior del IC para el parámetro \(\beta\).
IC.beta <-confint(modelo2)[2,]IC.beta
2.5 % 97.5 %
0.3038460 0.7180261
IC.OR <-exp(IC.beta)IC.OR
2.5 % 97.5 %
1.355060 2.050382
Es decir, con un nivel de confianza del 95%, por cada incremento de 1 cm en la anchura del caparazón el odds estimado crece entre 1.36 y 2.05 veces (o lo que es lo mismo, crece entre un 35% y un 105%).
10. ¿Cuáles son las predicciones de la proporción de satélites para cada valor de la anchura observada?¿Y el número esperado de satélites por hembra?
11. Representa gráficamente las proporciones observadas y las predicciones lineales y logísticas de las proporciones de satélites por cada anchura del caparazón.
12. Calcula la proporció estimada de cangrejos satélite para una hembra con anchura de caparazón de 28 cm. Calcula e interpreta un intervalo de confianza al 95% para la proporción verdadera.
anchura fit se.fit residual.scale
1 28 1.589535 0.290366 1
## Intervalo de confianza para el logitalpha <-0.05lim.inf <- data.pred$fit-qnorm(1-alpha/2)*data.pred$se.fitlim.sup <- data.pred$fit+qnorm(1-alpha/2)*data.pred$se.fitIC.logit <-c(lim.inf,lim.sup)IC.logit
[1] 1.020428 2.158642
## Intervalo de confianza para la probabilidadIC.prob <-c(plogis(lim.inf),plogis(lim.sup))IC.prob
[1] 0.7350560 0.8964736
2. Para entregar
Para estudiar cómo afecta una determinada droga sobre una especie de insectos, se realizó un experimento con 8 grupos de insectos a los que se les administró distintas dosis de dicha droga y se les midió:
la dosis administrada a cada grupo de insectos (\(x\))
el número total de insectos por grupo (\(n\))
el número de insectos muertos en cada grupo tras 5 horas de exposición a la droga
El objetivo es modelizar la proporción de insectos muertos en función de la dosis administrada. Los datos se recogen en la siguiente tabla:
Dosis
Insectos muertos
Total insectos
169.1
6
59
172.4
13
60
175.5
18
62
178.4
28
56
181.1
52
63
183.7
53
59
186.1
61
62
188.3
60
60
Responde a las siguientes preguntas:
2.1. Introduce los datos en R mediante la función data.frame.
2.2. Define una nueva variable llamada prop que indique la proporción de insectos muertos.
2.3. Ajusta el modelo probabilistico lineal \[\pi(x)=\alpha + \beta x\] donde \(y\) corresponde a la variable prop y \(x\) corresponde a la variable dosis
¿Cuáles son las estimaciones de los coeficientes? ¿Son estadísticamente significativos?
¿Cuál es el coeficiente de determinación? Explica su significado.
¿El modelo ajustado es estadísticamente significativo?
2.4. ¿Cuáles son las predicciones de la proporción de insectos muertos para cada dosis? ¿Y el número esperado de insectos muertos por dosis?
2.5. Representa gráficamente las proporciones observadas y las predicciones lineales de las proporciones de satélites por cada anchura del caparazón.
2.6. Ajusta el modelo de regresión logística \[\mbox{logit}[\pi(x)] = \log \left(\frac{\pi(x)}{1-\pi(x)} \right) = \alpha + \beta x\] donde \(\pi\) corresponde a la variable prop, y \(x\) a la variable dosis.
¿Cuáles son las estimaciones de los coeficientes? ¿Son estadísticamente significativos?
¿El modelo ajustado es estadísticamente significativo?
2.7. ¿Cuál es la tasa incremental de cambio para una dosis de 170? ¿Qué significa?
2.8. ¿Cuánto crece el odds estimado al aumentar la dosis del primer valor 169.1 al segundo valor 172.4?
2.9. ¿Cuáles son las predicciones de la proporción de satélites para cada valor de la anchura observada?
2.10. Representa gráficamente las proporciones observadas y las predicciones lineales y logísticas de las proporciones de satélites por cada anchura del caparazón.
2.11. Calcula la probabilidad estimada de que un insecto fallezca con una dosis de 185 unidades y su intervalo de confianza al 95% .